东京天气预报一周天气预报_东京天气预报准确
1.九月二十二至二十七日本东京地区的天气
2.有哪位朋友知道东京最近天气如何11月8号我要去日本东京但是不知道那边天气如何?要带些什么衣服呢?
3.解开“交叉熵”的神秘面纱
4.日本东京的天气怎么样
九月二十二至二十七日本东京地区的天气

日本>东京 天气预报
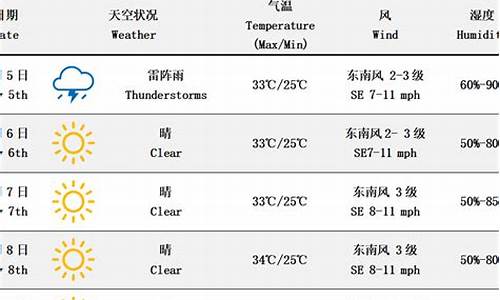
周四(22日)雨25℃/21℃
周五(23日)雨26℃/21℃
周六(24日)雨26℃/23℃
周日(25日)雨转阴28℃/22℃
周一(26日)雨27℃/20℃
周二(27日)阴24℃/19℃
有哪位朋友知道东京最近天气如何11月8号我要去日本东京但是不知道那边天气如何?要带些什么衣服呢?
11月8日最低气温12度,最高16度,晴天,东北凤2级
详细的你可以看这个网站,东京的天气预报天气跟上海差不多,带件外套就搞定了
解开“交叉熵”的神秘面纱
什么是交叉熵?和信息熵有什么关系?为什么它可以用作分类的损失函数?二分类的交叉熵怎么表示?
在分类任务中,你可能已经用过交叉熵来作为损失函数,并且好奇为什么要使用自然对数?二分类的交叉熵和普通的交叉熵有没有什么本质的不同?读完这篇文章,希望你会有所收获。
交叉熵,由“交叉”和”熵”组成,我们先来理解熵,再来理解什么是交叉。
所以,首先我们来复习下熵。更多熵的内容见上篇博客
无论是离散还是连续状态下,我们都是计算 负对数概率 的 期望 ,作为某事件 x 的理论上的最我码长度。
所以可以写成期望的形式:
x~P 表示计算P概率分布下的期望。
也可以写成H的这种形式。
总结一下,熵告诉了我们某事件在给定概率分布的情况下,理论上最我码长度。
也就是我们一旦知道了某事件的概率分布,我们就可以计算它的熵。
但是如果我们不知道该事件的概率分布,那么无法计算熵,那怎么办?我们是不是就得对熵做一个估计。
但是,熵的估计意味着什么?他的准确度怎么衡量?
为了回答这些问题,我们自然而然的引出了交叉熵。
还是以东京的天气预报为例子。但是我们不知道天气及具体的概率分布。为了便于讨论,假设我们观察了一段时间的天气,可以找出其概率分布。
起初我们不知道东京天气的概率分布,我们用Q来估计它,并用它来计算发送天气信息到纽约的最小平均编码长度。
利用估计的概率分布Q,那么估计的熵:
加入估计的Q越接近真实的分布,那么上面的估计也就越能到达最小的编码长度。
但是呢,熵的估计公式中包含两种不确定性。
如x~Q所示,我们使用估计的概率分布Q来计算期望,与实际概率分P计算出的期望不同。这是第一种不确定性。
此外,我们估计最我码长度为-log Q,我们根据估计的概率分布Q计算。因此,它不会100%准确,这是第二种不确定性。
由于估计概率分布Q影响期望和编码长度的估计,那么估计的熵可很大程度上也是不正确的。
碰巧的话,估计熵可以接近真实熵,因为Q影响期望的计算和编码长度估计。
所以,估计熵的真实熵之间的比较并不意味着什么。
和香农一样,我们关心的是怎么把编码长度变得尽可能的小。所以我们应该比较我们计算出的编码长度和理论上的最我码长度的大小。
如果在观察东京的天气一段时间后,我们可以获得实际的概率分布P,那么就可以利用概率分布P和天气报告期间使用的 实际编码长度 (基于Q)来计算实际的 平均编码长度 。
我们称其为:P和Q之间的交叉熵,和熵的公式进行比较。
我们将苹果与苹果进行比较,因为我们使用相同的真实分布来对计算期望。 在此我们比较理论上最我码长度和天气报告中使用的实际编码长度。
简而言之,我们正在交叉检查编码长度,这就是“交叉”在交叉熵中的含义。
通常,交叉熵如下表示:
H(P, Q) 表示利用概率分布P和基于Q的编码长度来计算期望. H(P, Q) 和 H(Q, P) 一般结果不相同,除非Q=P。在这种情况下交叉熵就成了熵本身: H(P, Q) = H(P, P) = H(P) 。
这一点很微妙但很重要。 为了计算期望,我们应该使用真实概率分布P, 对于编码长度,我们应该使用Q来编码消息。
由于熵是 理论 最小平均编码长度,因此交叉熵高于或等于熵但不小于熵。
换句话说,如果我们的估计是完美的,则Q = P,因此H(P,Q)= H(P)。 否则,H(P,Q)> H(P)。
到目前为止,我们搞清楚了熵和交叉熵之间的关系。 接下来,我们讨论下为什么交叉熵可以作为分类的损失函数。
例子:动物5分类问题,且每个值包含一种动物。
每幅都用one-hot的形式来编码。
对于第一幅图(小狗):
对于第一幅图(狐狸):
计算下每个图的熵,其都为0,也就意味着没有不确定性。
换句话说,one-hot编码的标签,以100%的确定下告诉我们中动物是什么。第一幅图不会出现90%是狗。10%的情况是狐狸的这种状况。它一直是狗,不会出现什么意外。
现在,我们有个模型来对这些进行分类。当我们对模型的训练程度不够时,对第一幅(狗)分类可能会出现如下的情况:
也就是目前的模型告诉我们这个图:40%-dog, 30%- fox, 5% - horse, 5%-eagle ,20% - squirre.看起来不是特别的准确来告诉我们到底是什么动物。
相反,标签为我们提供了第一张图像的动物类别的精确分布。 它告诉我们这是一只100%确定的狗。
所以,这么模型的预测能力怎么样?我们计算一下交叉熵。
假设模型由训练了一会,对第一幅图的输出为:
计算交叉熵,比之前的小了许多。
交叉熵将模型的预测和正式分布下对应的标签进行比较。 随着预测的越来越准确,交叉熵的值越来越小 。如果预测完美,那么交叉熵变为0。所以交叉熵能够作为分类模型的损失函数。
在机器学习中,我们经常以自然对数为底而不是以2为底的对数,其中原因之一是 便于计算微分 。
对对数的基的变化只是会引起幅度上的变化。在分类问题中,我们用交叉熵作为损失函数,相对于具体的值更关心的关注其变小的趋势。
纳特,是信息论中 熵 的单位之一。以自然对数为底而不是以2为底的对数,以2位底称为比特(bit)。
1纳特相当于1.44比特。
怎么理解1纳特?所以以 1/e 的概率的事件的信息量。1比特就是以1/2概率的时间的信息量。
但是以e为底解释起来没有像以2为底那么直观。比如我们对某个信息用1 bit编码,那么就降低了50%的可能性。如果用e来做相同的解释的话,并不是很好的去理解,这就是为什么常常用以 2为底 去对 信息熵 的概念做解释。然而,机器学习中偏爱自然对数是因为便于计酸。
情景:猫狗分类
日本东京的天气怎么样
12月25日的天气是阴转晴 最高气温14度 最低气温6度。
12月26日 晴转多云 10度 6度。
12月27日 晴有时多云 9度 1度。
12月28日 晴有时多云 11度 3度。
今天只能查到到28日东京的天气情况。
东京的冬季相对少雨与中国上海的天气比较接近,白天出门可以穿毛衣加一件稍
厚的外套,晚间出门可以穿毛衣加短大衣即可;太长的衣服会行走不便。如果是
年轻人的话下面穿一件保暖内裤加外裤即可,年纪大的人可以穿2件保暖内裤,
不需要穿毛裤。东京本土人冬季穿裙装的也为数不少。旅游景点应该都有决定了
在这里就不一一介绍了,楼上讲的日本温泉的确很舒服,有机会的话值得一
去。 好吧 祝你及家人旅途愉快 ,玩的开心 !
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。